Github Repository: https://github.com/juanito040102/NYC_Shooting_Incidents
Github Pages (Website) (Contains the Visuals): https://juanito040102.github.io/
NYC_Shooting_Incidents/
Project Topic
This project investigates the spatial and temporal relationships between shooting incidents in
New York City, The core objective is not to claim any conclusion on the cause or nature of these
incidents, but to visualize and analyze patterns that may reveal longstanding systemic
inequalities across NYC boroughs. The final deliverable will be a series of interactive plotly
visuals accompanied by a narrative that tell a data-driven story about the urban landscape of
violence and poverty. This project is to be expressed digitally, not in print, and in an interactive
way, not static. Ideally, this project could live in a repository in Github and later be developed
into a static website in which the visualizations maintain their ability to be interactive.
Dataset: NYPD Shooting Incidents
This dataset is obtained through NYC Open Data, and there are two complimentary pieces of
information; the Historic dataset that compiles the shooting incidents from 2006 until the end of
2024, and the active dataset that gathers the shooting incidents of this current year, 2025, up until
the day of accessing the data.
The Historic dataset and the YTD Dataset both have the same columns, but different amounts of
rows. The historic dataset has 29,744 incidents over the course of several years and the YTD
dataset has 769 incidents over the course of almost a year. This means that on average, the
historic dataset expects around 1.6 K records every year. When the datasets are combined, there
are 30,513 incidents over the course of 18 years and 9 months.
They both share the same 21 columns; Incident_Key, Date_Occurrence, Time_Occurrence,
Borough, Location_Occurrence, Precinct, Jurisdiction_Code, Location_Classification,
Location_Description, Murder_Flag, Perp_Age_Group, Perp_Sex, Perp_Race,
Victim_Age_Group, Victim_Sex, Victim_Race, X_Coordinate, Y_Coordinate, Latitude,
Longitude and Georeference_column.
These columns can be grouped into 3 categories; about the incident, about the people involved,
and the geography or location of the incident.
Introduction to Visualizations
This analysis is regarding public shootings in New York City from 2006 and 2025. As a foreigner
who now lives here, the culture and opinions surrounding the second amendment or the right that
Americans have to bare arms shocked me. There is freedom of action but not of consequence.Society in here sometimes seems to assume that because they require the right to bare arms then
some other individual will pass away over a firearm. The fact that this dataset has more than 30K
records is astonishing, and of course there is a lot to be said and done about this subject, and this
analysis could contribute more significantly to the current discourse, however my interest lies in
the seasonality of these incidents. Why is there a constant number of these events occurring? And
when do they occur more often? Because of this train of thought the analysis goes through
visuals regarding hours, days, months, years, and even all at the same time. Some patterns are
visible to anyone, even if there is no python knowledge behind.
How to interact and use these visuals: A tutorial on how to be a user of plotly.
1. Hovering over the data is useful. If it is a line chart, you can follow the trend with the cursor
and get insights on the values and how they were changing over time. If it were a bar chart or
a scatter plot, hovering over the figures will make a pop-up come up and show the user the
data point they were curious about.
2. Clicking on/off data points can be messy. As a user, it is natural to want to click and press
the cursor, but once the point is selected, all of the other data becomes transparent and not the
focus of the visual. Turning off a group inside a bigger variable can be insightful, and turning
it back on is just as easy, so playing with this function is pretty safe.
3. Zooming In/Out is different than the intuitive scroll. To zoom in on a visual, the user needs
to make two clicks, one as a starter point, and then drag the cursor around to generate a
window that once the user lets go, it will expand into screen and only show what the cursor
selected. To zoom back out there are two choices, the zoom buttons on the top right that can
help to go in and out, or the House icon, which is also conveniently on the top right corner,
and will take the user straight back to the original position of the visualization.
4. Nothing is going to break over the user interacting. The user may click and click but the code
for the visual remains intact, and if they just press the house button on the top right everything
will go back to normal.
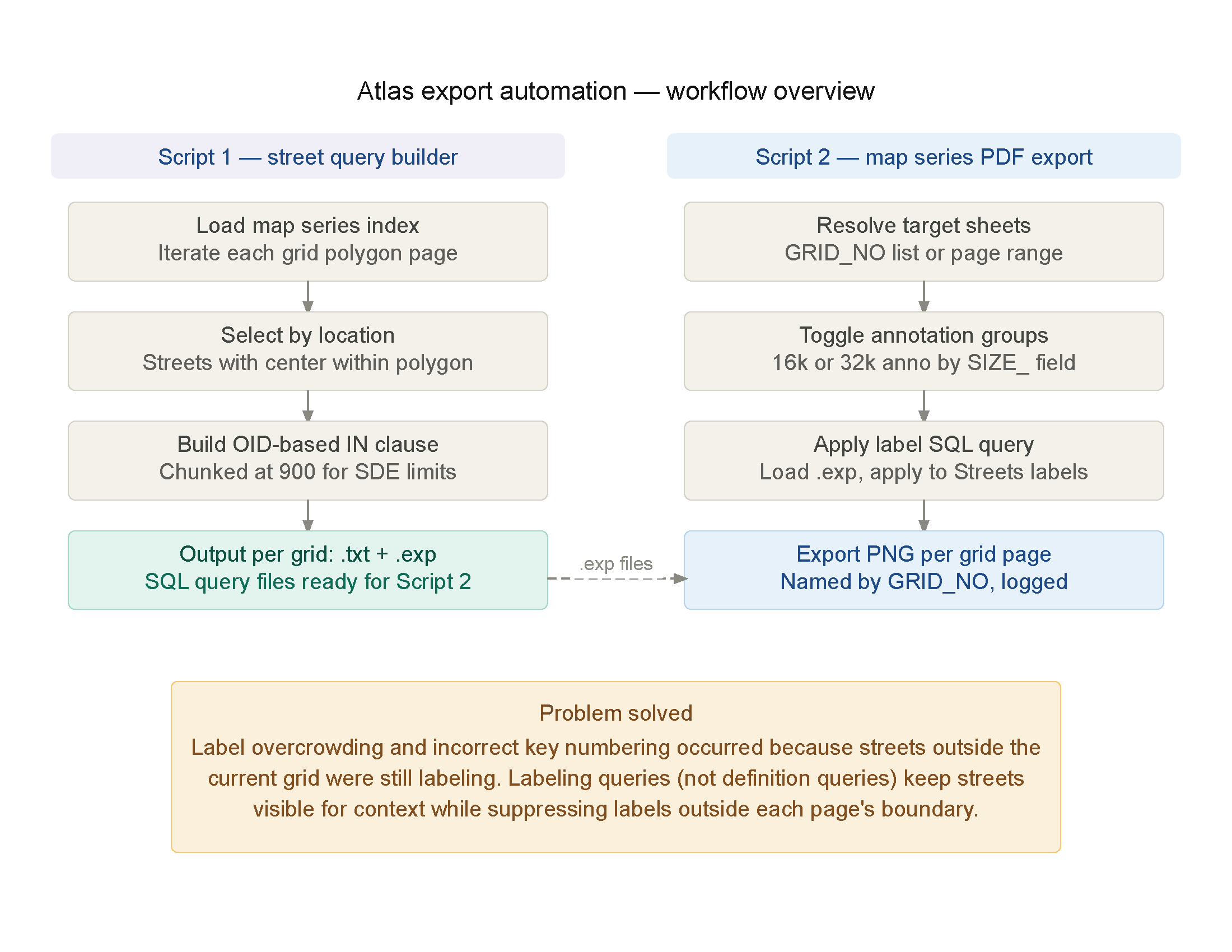
Methods, Tools and Processes
1) Microsoft Excel: Data Acquisition & Data Cleaning
Download the two datasets and remove the unnecessary row at the top and the additional sheets
that make python be able to read the dataset. Also there is an initial glimpse at the data that is
made in Excel because of how easy Pivot Tables can be to make.
2) Python Notebook
Python notebooks are used to analyze data and create visuals using the libraries pandas, numpy,
matplotlib and plotly (plotly.express).
For this analysis, the main tool used was a python notebook to clean the data types, combine the
two datasets, but mostly to generate insightful visuals. The main objective is to analyze the datathrough a temporal interest / lens. This means to study if the data has evident seasonality, or
frequencies that vary according to some sort of date/time information piece. On the other hand,
one or two visuals regarding the victim or perpetrator information could be of use / relevant to
complement the rest of the analysis. Additionally, this notebook has the task of creating an
interactive map visual in which the user can observe the incidents of one year, and still be able to
switch to visualize another year. Moreover, the user has to be able to hover over points and get a
pop-up of some of the data, and be able to zoom in and out of the map to go into detail or simply
see the big picture.
3) Github & Github Pages
Once the data is clean, the visuals are created, those plotly graphics can be transformed into
HTML code and be uploaded to a Github repository, accompanied by the notebook, a read me
file and other relevant documents to generate a static website that can host these visualizations
and be more accessible to a different audience that is not familiar with python notebooks.
Expected Design Products
Tools planned to use: Python Notebook (using pandas, numpy and plotly) into a github
repo with a read.me file.
Data Cleaning:
Column Types:
Int/Float (Numeric): id, precinct and jurisdiction code.
Object: date, time, boro, location occurrence, location classification, location
description, age / sex / race groups (for both vic & perp), latitude and longitude.
Boolean: Murder_flag
It is evident that date and time of occurrence should not be object type of data, and require to be
changed to a date time column on their own to be able to operate with the data. Using the
function ‘to_datetime’ from the pandas library it is possible to create a new column that uses the
‘date’ and ‘time’ strings to generate a new column ‘datetime’.
Categorical Columns:
The categorical columns are columns that have object type of data but it is relevant to analyze
them too. These columns are related to the incident; Borough, Location Occurrence, Precinct,
Location Classification and Location Description. There are other categorical columns in thedataset like: Perp Age Group, Perp Sex, Perp Race, Victim Age Group, Victim Sex, and Victim
Race.
Using the function ‘value_counts’ it is possible to obtained an ordered list of the different values
the column is possible to have and what their frequency in the dataset is. It is relevant to know
that the Combined Data frame has 30,513 incidents to spot which columns have any missing
values. Here are the number of incidents with their respective values, ordered by amount of
incidents.
• Borough: BK. (12K), BX. (9K), Q. (4.5K), M. (4K) and S.I. (0.8K). Missing Values = 0
• Precinct: not relevant to this iteration of this analysis. Possible recommendation or next step.
• Loc_Occur:Outside (4,158), Inside (759), Missing Values (25,596). Not Useful.
• Loc_Class:Street (3K), House (0.8K), Others (1K), Missing Values (25.6K). Not Useful.
• Loc_Desc: Multi Dwelling (5.3K), Others (6.4K), Missing Values (18.7K).Not Useful.
• Perp_Age: 18-24 (6.8K), 25-44 (6.6K), under 18 (1.9K), Missing Values (14.4K). Not Useful.
• Perp_Sex: Male (17.3K), Female (0.5K), Missing Values (12.7K). Not Useful.
• Perp_Race: Black (12.7K), Hispanic (4.3K), Missing Values (13.0K). Not Useful.
• Vic_Age: 25-44 (14.0K), 18-24 (10.9K), under 18 (3.2K), other (), Missing Values (70).
• Vic_Sex: Male (27.5K), Female (3.0K), Intersex (1), Missing Values (12)
• Vic_Race: Black (21.5K), White Hispanic (4.6K), Black Hispanic (3.0K), White (0.8K),
Asian/Pacific Islander (0.5K), Native (0.01K), Missing Values (73)
3) Missing Values: there are non variables pertinent to this analysis that have a very high number
of missing values. The variable that do have a lot of missing values are not relevant to this
analysis in this iteration.
UX Research
Observations, Tasks, Interviews. Two People
Who, What, How?
• Who: Primary: One LIS Student with little python knowledge. Secondary: Another person that
does not know the tools at all. They need to be able to follow the story.
• What:
5. Comprehension: are users able to understand the visuals and the map?
6. Usability: can users hover for details, and navigate the visualization without instructions?
7. Insight & Value: What is the user’s main takeaway?
8. Missing Information: What other analysis did the user suggest is complimentary to this one?
• How: Two interviews last 30 minutes each. One simple task for each visualization.
1. Observe: Hesitations? Pain Points?
2. Feedback Survey: 5 point scale for understanding. Any difficulties?LIS Student (Interviewee 1)
Narrative: they understand narrative and story. They think the topic is controversial.
Map: they understand the map but had questions about the data.
Usability Visuals: at first they did not understand the zoom function. With a tutorial from the
interviewer they understood and recreated the function easily.
Usability Map: hovered and clicked accurately with no hesitation and little instruction, only
telling them that there was a hover and zoom feature. Were able to visualize the different data
points and information shown.
Missing Information: analysis on police surveillance and the relationship of these two variables
My sixteen year old sister who’s never been to New York (Interviewee 2)
Narrative: they understand the story. They find the information to be eye-opening
Map: Liked the map. Does not change per year, the year functionality does not add a lot to the
visual.
Usability Visuals: Had a little trouble with the zoom.
Usability Map: Hovered and clicked on points and switched the years very easily.
Missing Information: Wanted more information about the prosecution and the perpetrators
outcome of the case.
Findings both of the Visualizations and the UX Research
1. Figure: Daily Occurrences Over Time
This figure is a line chart that shows there is initially some seasonality to the data because if the
user can observe the pattern that repeats, with the low number of incidents happening during
winter, and the high number of incidents occurring during the summer of each year.
Also this figure shows two dates that could explain some of the variability. The first one is a
marker for July 4th 2020, which was the day with most incidents in the whole dataset, 47 in one
day. This phenomenon probably occurred because of the combination of the summer and the
pandemic, people were inside during lockdown, and during the summer especially July 4th the
people went out a lot.
2. Figure: Occurrences by Hour of the Day
This figure is a vertical bar chart that illustrates how the different hours of the day have different
amount of incidents. It is striking the different values that a change of one hour make. The lower
values are in the hours people go to work, between 5AM and 14PM. The highest point in the
chart is 11PM. Between 14PM and 11PM the number of incident rises on average 200 points.
3. Figure: Occurrences by MonthLine chart that shows the total number of incidents per month. The lowest point is February
(1.6K) The highest is July (3.6K)
4. Figure: Heatmap.
The heat map shows the average number of incidents per month per year. He highest value on the
whole table is July 2020, with an average of 10.5 incidents per DAY. The lowest month was a tie
between March 2017, February 2020 and February 2025, all with an average of 2 incidents per
day.
If you look at the heat map horizontally, it is apparent that the summer months have the highest
averages on average, except for 2017, 2018 and 2019. It is also apparent that January and
February are expected to be low values on average every year.
If you look at the heat map vertically, the 2017-2019 period stands out as a moment in this heat
map when whole years had averages below 5 incidents for every month. It is also noticeable that
these past few years have been very low averaged. Since 2023 there is not a month with more
than 5 incidents per day on average.
The two clouds that appear at first sight are June-September from 2006-2012. The other cloud is
May-September of 2020-2022. Pandemic.
5. Figure: Top 20 Dates with most incidents
All during the summer. Varied In years.
6. Figure: Stacked Vertical Bar Chart: Total Amount of Incidents by Borough colored by race of
the victim.
Brooklyn at the top, bronx second, queens third, Manhattan 4th and staten island last. Most
incidents the victim has been black. Both white hispanics and black hispanics are in second and
third place across all boroughs.
7. Figure: Scatter Plot: Victim Age, Sex, and Race
The biggest bubble is black men in their 25-44 (9039). The second biggest group is black men in
their 18-24 (7193). After that its black men under 18 (2013). After that the race changes but the
sex does not. White hispanic men in their 25-44 (1925), after that its the same group but in their
18-24 (1505). Then we switch races again to black hispanic. In their 25-44 (1229) and 18-24
(1005). Under 18 its around 300 for both hispanic groups.For women, its black women in their 25-44 (766) and in their 18-24 (628), after that is under 18
(330) and 45-64 (222). If we switch to white hispanic women, the highest value is in the group
from 25-44 (241) and then 18-24 (132).
8. Figure: Map ALL
9. Figure: Map per Year
Findings Regarding User Experience:
1. Lack of Transversal analysis. The interviewees would have liked that data be combined and
cross-analyzed with other lateral datasets, so that the analysis seemed richer and more
complex.
2. Sometimes the user needs a tutorial because the audience for this analysis is small; it is for
someone who knows a little python but does not know any visuals or any principle of design.
In retrospect, the analysis could have been complex and intense, having simple visuals or also
difficult to execute and understand ones.