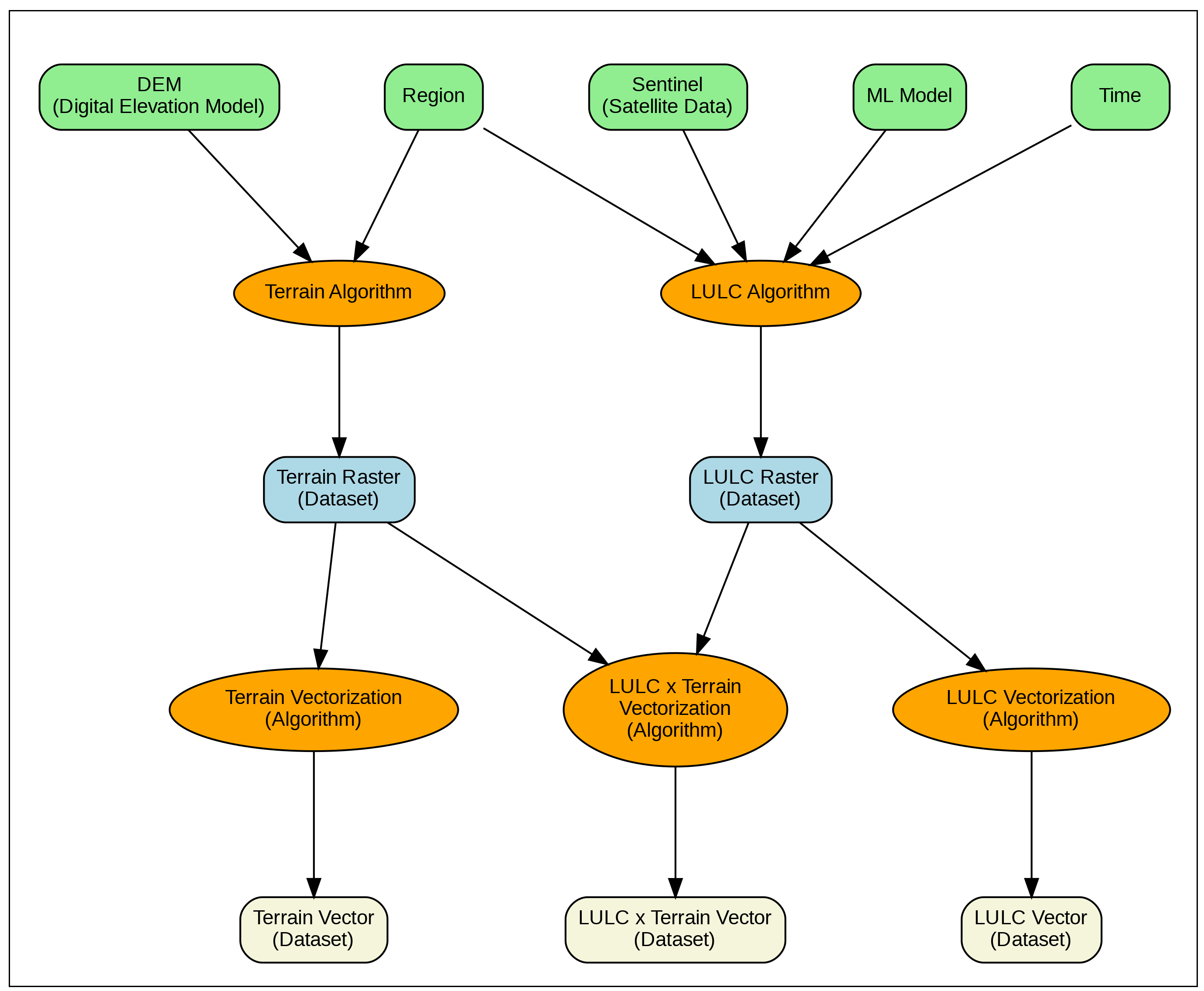
Working with geospatial data is like cooking a complex meal with many ingredients and steps. You start with raw satellite imagery, digital elevation maps, and machine learning models, then process them through multiple algorithms to create useful outputs like land-use maps or terrain classifications. But here's the problem: when you update one ingredient or change how you cook something, it's nearly impossible to track which dishes need to be remade.
This challenge affects everyone working on environmental monitoring, climate analysis, and sustainable development projects. Researchers waste time recomputing entire workflows when only small parts have changed, and it's difficult to reproduce scientific results because we don't have good records of how datasets were created.
The Problem with Current Standards
The geospatial community uses a popular standard called STAC (SpatioTemporal Asset Catalog) to organize datasets. While STAC is excellent for finding and sharing individual datasets, it has a critical limitation: it only tracks direct parent-child relationships between datasets. If you want to know the complete history of how a dataset was created which algorithms were used, what versions, what input parameters STAC doesn't capture this information systematically.
Our Solution: STACD
We developed STACD (STAC Extension with DAGs), which adds workflow awareness to the STAC standard. The key insight is to represent geospatial processing workflows as Directed Acyclic Graphs (DAGs) essentially, flowcharts that show how data flows through different processing steps.
STACD extends STAC with three main capabilities:
Complete Lineage Tracking: Every dataset records not just its immediate parents, but the entire chain of algorithms, input datasets, and parameters used to create it. This is like having a complete recipe that includes not just the ingredients, but every cooking step, temperature, and timing.
Algorithm Versioning: STACD introduces a formal way to describe algorithms and their versions. When you update a terrain classification algorithm or switch from one machine learning model to another, the system tracks which datasets need to be recomputed.
Selective Re-computation: Instead of rerunning everything, STACD identifies exactly which parts of a workflow are affected by changes. If you update your elevation data source, only the terrain processing branch needs to run again your land-use analysis can stay untouched.
Implementation and Real-World Use
We built a reference implementation using Apache Airflow, a popular workflow management tool. Our system maintains a database that tracks every algorithm execution, records complete lineage information, and provides visualization tools to understand complex dependencies. We're now migrating the CoRE stack pipelines to use this approach.
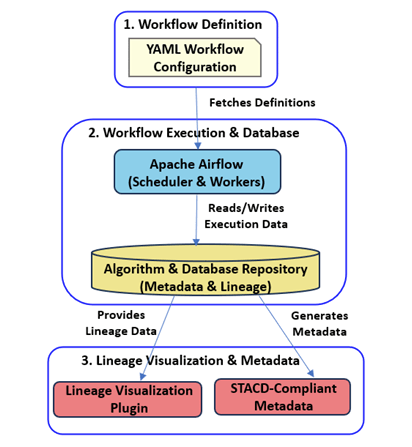
The practical benefits are significant. When we demonstrated STACD with a real workflow processing terrain and land-use data, we showed how updating just the satellite imagery automatically triggered reprocessing of only the affected outputs, saving substantial computation time and resources.
Looking Forward
STACD opens exciting possibilities for collaborative geospatial computing. Imagine a global registry where researchers can share not just datasets, but complete processing workflows. Different institutions could pool computational resources and reuse each other's algorithms, creating a decentralized infrastructure for planetary-scale environmental analysis.
This work represents a step toward more reproducible, efficient, and collaborative geospatial science. By standardizing how we track data lineage and algorithm dependencies, we can build more reliable systems for addressing critical environmental challenges.
Paper: [STACD:STAC Extension with DAGs for Geospatial Data and Algorithm Management]
Code: [STACD-Airflow Reference Implementation]
Published at PROPL 2025 (Programming for the Planet workshop, co-located with ICFP/SPLASH)