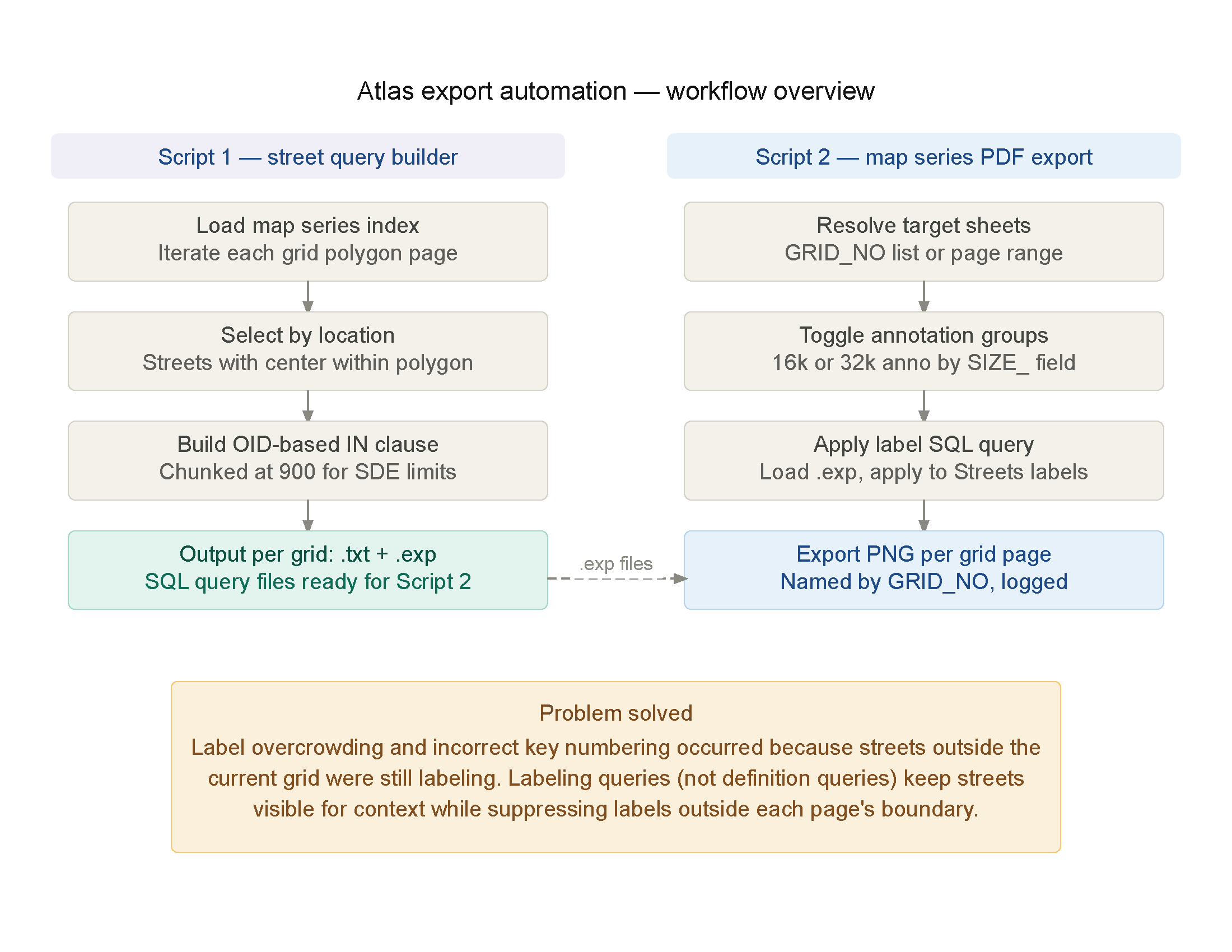
Working on forest carbon estimation using GEDI L4A satellite data, I ran into some interesting performance trade-offs between streaming and downloading approaches that might be useful for others working with large NASA datasets.
🔧 THE SETUP
Using the earthaccess library to extract 33 GEDI L4A biomass granules covering a specific region of interest, thus applying filtering. The workflow starts with STAC catalog discovery and file pointers definition:
# STAC-based discovery (same for both approaches)
import earthaccess
import pystac_client
earthaccess.login()
# Connect to NASA's CMR-STAC catalog
nasa_catalog = pystac_client.Client.open(
"https://cmr.earthdata.nasa.gov/stac/ORNL_CLOUD"
)
search = nasa_catalog.search(
collections=["GEDI_L4A_AGB_Density_V2_1_2056"],
bbox=roi.total_bounds,
datetime=TIME_RANGE,
)
print(f"Found {search.matched()} granules")
# Helper function to select optimal download URLs
def get_preferred_url(item):
"""Get best available URL from STAC item assets.
Preference: HTTPS (cross-region) -> S3 (AWS region-specific) -> others
Each STAC item can have multiple asset URLs (S3, HTTPS, etc.)
"""
h5_assets = [a for a in item.assets.values() if a.href.endswith(".h5")]
# Prefer HTTPS URLs for broad accessibility (s3 may be limited region-wise)
for preferred_prefix in ["https://data.ornldaac.earthdata.nasa.gov", "s3://"]:
for asset in h5_assets:
if asset.href.startswith(preferred_prefix):
return asset.href
return h5_assets[0].href if h5_assets else None
# Extract optimal URLs from STAC items
urls = [
url for item in search.items()
if (url := get_preferred_url(item)) is not None
]Now, imagine that you want to perform some minimal data selection over each GEDI beam, note that it can be generalised to any other use case.
def extract_beam_data_optimized(f, beam, quality_filter=True, bbox=None):
"""Extract data from a single beam with HDF5-level filtering"""
beam_group = f[beam]
land_cover = beam_group['land_cover_data']
# First, check quality flag if filtering enabled
if quality_filter:
quality_flags = beam_group['l4_quality_flag'][:]
valid_indices = np.where(quality_flags == 1)[0]
if len(valid_indices) == 0:
return pd.DataFrame() # Return empty if no valid data
else:
valid_indices = slice(None) # Use all indices
# Load only valid data using advanced indexing - MAJOR MEMORY SAVINGS
data = {
'latitude': beam_group['lat_lowestmode'][valid_indices],
'longitude': beam_group['lon_lowestmode'][valid_indices],
'delta_time': beam_group['delta_time'][valid_indices],
'agbd_mg_ha': beam_group['agbd'][valid_indices],
'agbd_se': beam_group['agbd_se'][valid_indices],
'elevation_m': beam_group['elev_lowestmode'][valid_indices],
'quality_flag': beam_group['l4_quality_flag'][valid_indices],
# GEDI 1 km EASE 2.0 grid Plant Functional Type (PFT) derived from the MODIS MCD12Q1v006 Product.
# Values follow the Land Cover Type 5 Classification scheme.
# https://lpdaac.usgs.gov/documents/101/MCD12_User_Guide_V6.pdf
'pft_class': land_cover['pft_class'][valid_indices],
# The percent UMD GLAD Landsat observations with classified surface water between 2018 and 2019.
# Values > 80 usually represent permanent water while values < 10 represent permanent land.
'water_persistence': land_cover['landsat_water_persistence'][valid_indices],
'shot_number': beam_group['shot_number'][valid_indices],
'beam': beam
}
...From here, you can take two different processing paths.
🌐 APPROACH 1: Remote Streaming with earthaccess.open()
The streaming approach that filters and processes data by downloading it on the fly.
# Stream files directly from NASA servers
file_pointers = earthaccess.open(urls)
# Process each file in streaming mode
for fp in file_pointers:
with h5py.File(fp, "r") as f:
processed_data = ... # Filter/process HDF5 data directly from remote stream💾 APPROACH 2: Local Download with earthaccess.download()
Download first, then filter and process locally with concurrent workers:
# Download all files to local storage
download_dir = Path("./gedi_data")
downloaded_files = earthaccess.download(
urls,
local_path=str(download_dir)
)
# Process with fast local I/O + multiprocessing
from concurrent.futures import ProcessPoolExecutor
def process_local_file(args):
file_path, roi_bbox = args
with h5py.File(file_path, "r") as f:
processed_data = ... # Same filtering/processing logic, but with local files
return processed_data
with ProcessPoolExecutor(max_workers=4) as executor:
process_args = [(f, roi_bbox) for f in downloaded_files]
results = list(executor.map(process_local_file, process_args))📊 PERFORMANCE RESULTS
Testing with 33 GEDI granules (~10GB total):
Remote Streaming (earthaccess.open):
Runtime: did not finish
Reliability: Possible timeouts
Memory usage: High (loads entire arrays before filtering)
Error handling: Complex retry logic needed
Reusability: Must re-stream for different analysis
Local Download (earthaccess.download):
Runtime: ~10 minutes
Reliability: Highly reliable
Memory usage: Lower (can filter at HDF5 level)
Error handling: Straightforward
Reusability: Process same data multiple ways without re-download
🔍 WHY THE DOWNLOAD APPROACH WORKS BETTER
Network vs Storage Trade-off: Modern SSDs can read at 3-7 GB/s, while HTTP downloads typically max out at 100-500 MB/s. Once downloaded, local processing is much faster.
Failure Recovery: Network timeouts require full restart with streaming. With local files, you only need to re-download failed files.
HDF5 Chunk Alignment: When streaming, you often need to download entire chunks even if you only need filtered subsets. Local access allows more efficient partial reads.
Multiprocessing: Parallel processing works reliably with local files but can be problematic with remote streams due to connection limits.
🎯 WHEN TO USE EACH APPROACH
Use earthaccess.open() when:
Quick exploratory analysis
Small datasets or specific file subsets
Cloud computing with good network connectivity
One-time processing workflows
Use earthaccess.download() when:
Large datasets
Production workflows requiring reliability
Iterative analysis on the same data
Complex processing requiring multiprocessing
Limited or unreliable internet connectivity
The STAC discovery workflow remains the same regardless of processing approach, which makes earthaccess particularly nice to work with. You can easily switch between strategies depending on your specific use case.
For anyone working with NASA Earth science data, I'd recommend benchmarking both approaches with your specific datasets and network conditions. The "optimal" choice often depends more on your infrastructure and workflow requirements than the theoretical efficiency of the approach.